The inventor and visionary Ray Kurzweil, who coined the very term “singularity”, based his predictions on observation that today’s world is not linear. “Our brains are linear. They developed to predict the future, but the kind of challenges we had 50,000 years ago when our brains were evolving were linear ones. We looked up and said, that animal’s going that way. I’m coming up with a path this way. We’re going to meet at that rock. That’s not a good idea. I’m going to take a different path. That was good for survival. That became hardwired in our brains. We didn’t expect that animal to speed up. As we went along, we made a linear projection. We used to apply models that use the old linear assumption. But not in our modern world.”
This came up to my mind when I was watching Marco Trombetti from Translated sharing on recent SlatorCon a graph of average post-editing time decrease that they were collecting since 2015 to date and extrapolates it to “singularity” by 2028 as linear extrapolation.
Well guess what – this extrapolation is definitely incorrect, because you should not extrapolate improvement in AI models with linear function. Why? Because it’s a well-known fact that the cost of improvement of AI system grows exponentially as you try to halve error rate:
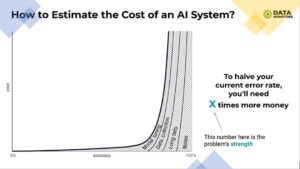
This is confirmed by the real world scenarios of training larger and larger models; yet the quality grows only little by little.
We have recently fine-tuned a supermegatransformer model of WMT21 by META AI (http://ai-lab.logrusglobal.com/tuning-meta-ai/), and discovered that MT output quality increase is not that dramatic compared to much more simple Marian baseline and fine-tuned model:
MarianMT_init_translations_with_hlepor: 0.3690639855690041
MarianMT_tuned_translations_with_hlepor: 0.487768427660078
WMT21_init_translations_with_hlepor: 0.475542272611778
WMT21_tuned_translations_with_hlepor: 0.59922126791889
As you can see, going from 7.6 million to 4.7 billion parameters over several years (and from regular GPU to a massive supercomputer) only increased hLEPOR from 0.49 to 0.6.
That’s why in reality the post-editing time (and date of arrival of Singularity, for that matter) should not be done by linear extrapolation, but with ever more decreasing speed of improvement, and in fact singularity may never be achieved, because it is getting increasingly much more and more difficult.
At this level of data collection and data reliability the same graph can be extrapolated with many completely different curves, and it’s hard to know which one is the best fit, because the reliability of such forecast is so low; but one thing is certain: it’s not a straight line, but rather, a decelerating curve, like the red one I drew on his chart, on top of linear prediction:
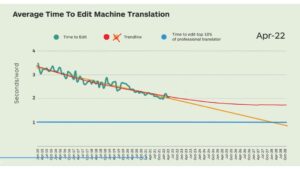
We’ll see what the time will show, but our own experiment of fine-tuning megatransformer, as well as empirical experience of the cost of error rate decrease for AI models are datapoints on the red curve.