On November 10, 2021 Meta AI Research published article “The first-ever multilingual model to win WMT, beating out bilingual models” [1]. This work claimed breakthrough achievement – for the first time a single huge multilingual model of scale (“WMT FB AI Multilingual”) has outperformed the best specially trained bilingual models across 10 out of 14 language pairs.
This is just one in the series of large language models which have been rolled out recently and continue to be deployed and trained:

Fig.1 Meet The New Hype – large language models.
As you can see, the new hype of large language models is out there and all serious companies are moving in this direction, and the reason is that the WMT21 definitely demonstrated a very promising result in many ways.
So we also dared trying to fine-tune this model to see how it performs not only on general news items (which is what it has been made for), but for specialized automotive domain.
Our plan of such an experiment was simple:
- Import domain-specific dataset.
- Run test part on pre-trained model, measure BLEU.
- Fine-tune the model on training part of the dataset.
- Run test part on fine-tuned model, measure BLEU and compare.
- Do the same on Marian.
- Apply proper metric (better than BLEU) to measure translation quality and compare the results.
- Repeat 1-6 on few other domain specific datasets
The first problem that we have encountered is the size of the model. Marian, arguably the most popular pretrained model, has 7.6 million parameters and can be fine-tuned on Colab or AWS at virtually no cost.
FB AI WMT21 model (wmt21-dense-24-wide-en-x) is a “megatransformer” with 4.7 billion parameters, it’s 618 times bigger than Marian and this means that it will not fit into regular GPU. So we had to find a much larger GPU (we used an expensive NVIDA A100 with 80GB VRAM) than it is generally available for AI/ML enthusiasts.
Another problem was that standard fine-tuning scripts that came with the model did not work. It took a lot of high-end tweaking to change them properly. It took us some time to overcome these issues.
However, the first results that we’ve got were quire promising.
Here are the numbers for Marian “baseline” model – before training the quality was only 7.377:
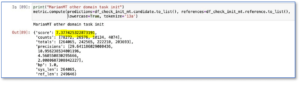
Fig.1 Marian pre-trained model on test dataset prior to fine-tuning.
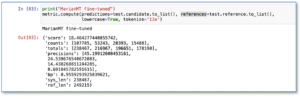
Fig.2 Marian fine-tuned model on test dataset demonstrates significant 2x improvement
The FB AI WMT21 model demonstrated better baseline quality out of the box:
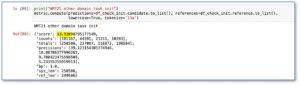
Fig 3. FB AI WMT21 pre-trained model on test dataset prior to fine-tuning.
Then the fine-tuning raised score to 24.49:>
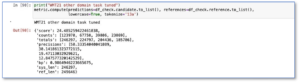
Fig.4 FB AI WMT21 pre-trained model on test dataset after the fine-tuning.
One could say that all these numbers seem low. This requires explanation.
Traditional BLEU has a huge problem – in fact, all BLEU measures could be different (because decoding/tokenization left outside of BLEU – it’s up to researcher how to do it). They are so different that standardized approach was proposed, called SacreBLEU [2]: “Every decoder has its own implementation, often borrowed from Moses, but maybe with subtle changes. Moses itself has a number of implementations as standalone scripts, with little indication of how they differ (note: they mostly don’t, but multi-bleu.pl expects tokenized input). Different flags passed to each of these scripts can produce wide swings in the final score. All of these may handle tokenization in different ways. On top of this, downloading and managing test sets is a moderate annoyance.
SacreBLEU aims to solve these problems by wrapping the original reference implementation (Papineni et al., 2002) together with other useful features.”
So the first reason is that this score is SacreBLEU, which is lower than various proprietary BLEU implementations. (And the reason it is lower is that SacreBLEU has standard tokenizer which is not optimal for every particular dataset, but it’s standard and that gives you consistency in scores.)
Another important reason is that we are tuning MT system on a very “vertical”, specialized domain and dataset, which is not something the engine was tuned to as a baseline. For specialized, real world technical dataset the numbers are much more modest.
What is important – as we can see, the FB AI WMT21 model quality boosted 100% after the fine-tuning on domain-specific content.
To double-check that we have got correct quality scores, we additionally measured resulting test datasets with hLEPOR automatic quality metric [3], which we have ported to Python last year and made freely available to public on http://pypi.org.
The results proved to be as follows:
|
MarianMT_init_translations_with_hlepor: 0.3690639855690041 MarianMT_tuned_translations_with_hlepor: 0.487768427660078 WMT21_init_translations_with_hlepor: 0.475542272611778 WMT21_tuned_translations_with_hlepor: 0.599221267918892 |
As you can see, hLEPOR also shows significant improvement of a fine-tuned model over the baseline.
But how universal and scalable is a solution to fine-tune generic megatransformer for particular domain?
We have found the answer in Yasmin Moslem article [4], which says:
Fine-tuning an NMT model usually consists of two steps:
-
- Building a baseline NMT model, e.g. a generic model.
- Continuing training the baseline NMT model on an in-domain dataset.
However, fine-tuning in this way can lead to “catastrophic forgetting”, i.e. the model overfits the in-domain data, starts forgetting the information learned from the baseline data, and loses generalization. So in practice, when you compare its quality to the baseline model, the in-domain model would give a better BLEU score and human evaluation for translation of sentences similar to the in-domain dataset, but worse BLEU score for out-of-domain sentences.
In other words, when we fine-tune generic large transformer model on in-domain data, it becomes better in this domain, but starts forgetting information learned from baseline training data, and loses generalization – i.e., becomes worse outside of this particular domain.
For multilingual model this also means that other language pairs will also suffer.
However, even despite understanding that fine-tuning megatransformer is a “local” solution for a concrete domain in one language pair, the boost in quality may make this worthwhile.
With this understanding we proceed further to evaluation and comparison of what we’ve got, and more fine-tuning experiments.
Stay informed by subscribing to our blog and newsletter for this and other research updates!
_________________________________________________________________________
References:
[2] https://github.com/mjpost/sacrebleu
[3] https://pypi.org/project/hLepor/
[4] https://blog.machinetranslation.io/domain-adaptation-mixed-fine-tuning/