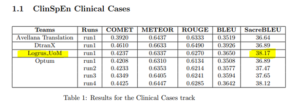
Last two weeks we participated in BiomedicalMT challenge for wmt22, and our MT model leads in Clinical Cases category, as shown in official results:
===
initial results from BiomedicalMT including ClinSpEn2022 is out on the wmt22 website https://www.statmt.org/wmt22/biomedical_results.pdf
we have sacreBLEU number 1 ranking in Clinical-Cases. 🙂
Fair-play, guys!
===
Great news!
We indeed were planning to demonstrate results among the leaders, … but we were hoping for something totally different.
There’s something really surprising in the results that we’ve got, and that surprising thing is that we won with the smallest and simplest model!
In fact, the model that took the first place in this challenge were planned only as a reference.
For this Biomedical WMT22 challenge we fine-tuned three pre-trained models:
Marian Helsinki – 1.7 million parameters,
WMT21 – a hypertransformer, 4.7 billion parameters,
NLLB – a hypertransformer, 54 billion parameters.
To fine-tune these models, we have prepared (collected and cleaned) a training corpus with 250,000 sentences from biomedical domain.
The results were evaluated with built-in metrics on organizers’ system Codalab, which were automatically calculating several scores for each dataset.
All three models fine-tuned successfully, and we have got these automatic scores at submission, as follows:
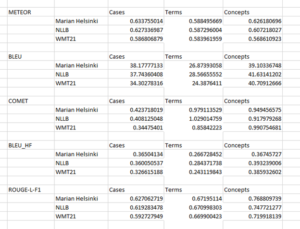
If you have a look at this, these results are nothing short of amazing.
Why?
In recent years the race was out there to train bigger and bigger models, in hope for quality improvement. This is noted in many industry presentations, such as Slator, for example, as shown in screenshot here: http://ai-lab.logrusglobal.com/tuning-meta-ai/
However, automatic metrics produced on submission by Codalab do not show any breakthrough in quality between these models, as it can be seen from this table above.
How is this possible? It’s really hard to believe that the much, much smaller model perform better from quality point of view, because it was trained on radically smaller dataset than hypertransformers.
Indeed, all three pre-trained models were fine-tuned on the same clean and neat dataset.
Indeed, the quality of this dataset is proven by the fact that Marian-Helsinki model fine-tuned by this dataset demonstrated outstanding performance.
But how is this possible that 54 billion parameters hypertransformer does not perform better and in fact performs worse than our reference, simple and small model?
One obvious hypothesis would be that automatic metrics do not, actually, measure quality. They measure only some sort of similarity between MT generation and golden standard they compare with.
Therefore, a human judgment experiment is required to really assess and compare the quality of these systems.
It looks like automatic metrics reached the end of their usable life. They clearly do very little to distinguish between totally different models primed to their best for certain concrete purpose, even on the same training and test dataset.
It looks like there’s still a lot to work on with automatic metrics, because any one of the metrics listed above call for criticism of its own, and all together they can’t be used to see what model is actually better.
Watch for this blog and subscribe to our newsletter to learn more very soon!