As 2023 draws to a close, it’s a perfect time to talk about year-end results – and we have something very special up our sleeve.
It would not be an exaggeration to say that this past year was the year of all things GenAI. The initial successes of OpenAI and its ChatGPT had raised a wave of veritable hype: we were promised everything, from the advent of AGI to the complete overhaul of the job market and the very foundations of society. Many people were in all earnestness discussing the “intelligence” of AI, and the previous generation of machine translation technology was under threat of disruption by GenAI.
But as the year wore on and more and more people started to realize that there is no more intelligence in GenAI than in MT of the previous generation, and actually previously deployed MT models perform in production faster and more reliably, and they also are much more suitable for industrial production workflows.
Still, new GenAI capabilities definitely can be harnessed to augment proven MT technologies, where all MT output must be verified. And, while both MT and GenAI still are nothing more than a string of words pieced together with no thought behind them, GenAI showed potential to help further improve MT production. MT translations are never perfect as they suffer from hallucinations, incorrect terminology, factual and accuracy errors. They need to be reviewed and verified by human professionals. However, reviewing MT output is a difficult task in itself because the reviewers have to battle the machine’s fluency that may hide the errors. Could we somehow improve this process, for example, with GenAI? Enter our R&D department.
Here’s what we did this year. First, we reviewed troves and troves of data and confirmed that even for languages that MT doesn’t handle too well, there is a significant portion of translation segments that are not changed after human review. Depending on the language, that figure ranges between 10% and 70%. So, we decided to run an experiment to see whether we could train the GenAI model (which is more versatile than production-level custom-trained neural MT) to predict whether MT output has to be post-edited. Unlike many attempts at quality metrics where you ask AI to rate a translation, the system we envisioned is binary – it’s either yes or no, without any additional analytic drill.
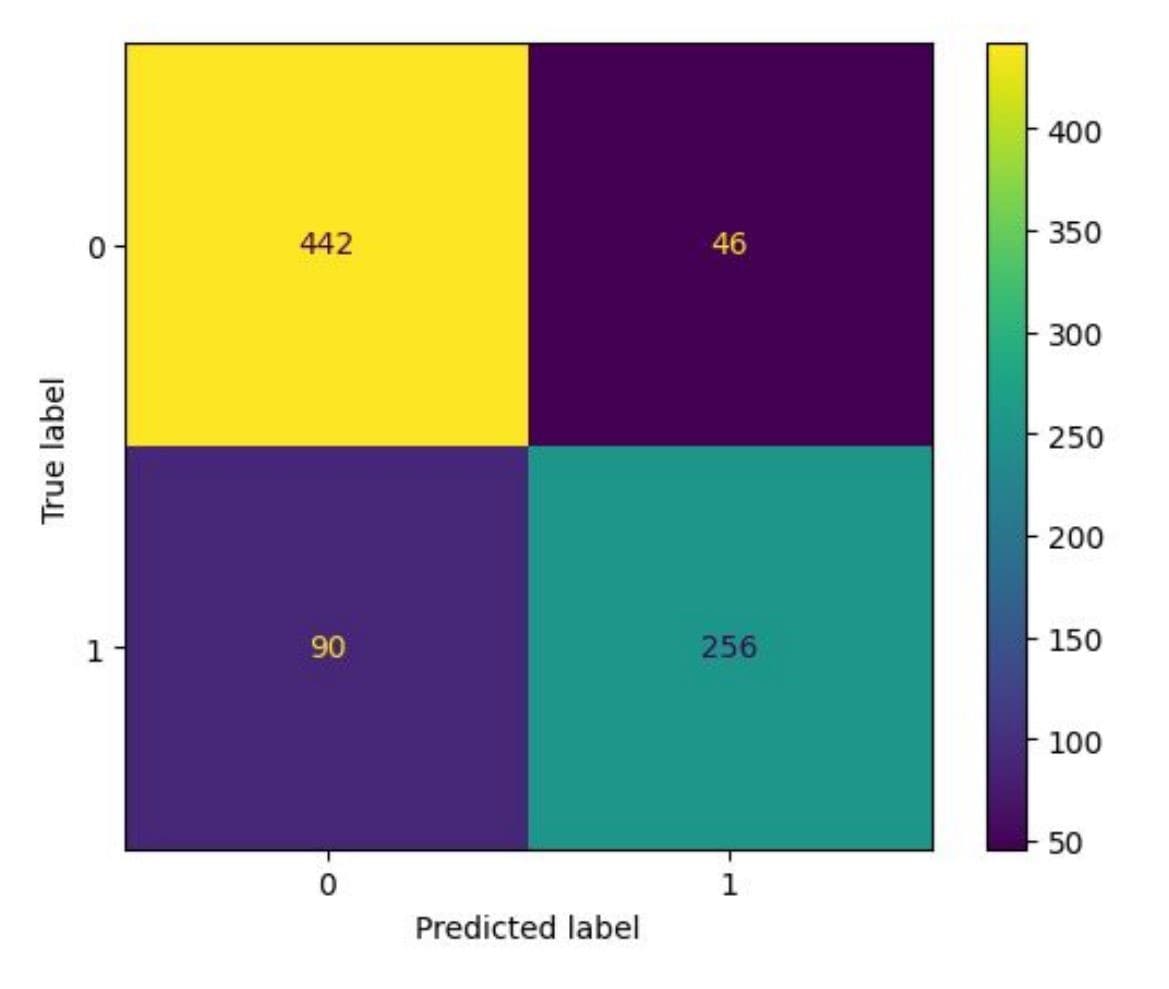
Here’s how we did it. We took the data from our previous eight language project. We had the original English text version, the results of machine translation, and the final version after the human review. We split the data into a large training dataset that contained approximately 35,000 words of original text, 35,000 words of MT output, and 35,000 words of post-edited text for reference and a smaller testing dataset. We then fine-tuned OpenAI’s curie model through the API for the task of classification. We taught the LLM to predict whether a specific translation segment needs to be reviewed by a human or not. The experiment was so successful, we were able to showcase it first at the customer’s internal event, and then at AMTA-2023, where we did a presentation. (The detailed description of the experiment and the thinking behind it is available here.)
Why is this important? Because this is a tangible proven tool that can make MTPE truly productive. By correctly determining which segments do not require human review and post-editing, companies can save a lot of time and money, concentrating their experts’ efforts on the parts that do need additional work. Why was our experiment successful? Because we taught the model to predict the need for post-editing, not to evaluate quality, edit or translate. Using curated training input, the machine learns to assess whether the translator will edit the segment in question or not.
So, here’s our result for 2023. We started with the assumption that GenAI is a powerful tool, not a final solution. We took curated datasets and trained an LLM fine-tuning it through API. We created a precise tool that can do one job, but it can do it well, saving the users time, effort, and money in the process. Get in touch with us in 2024 if you want to see how it works for yourself. Email us at rd@logrusglobal.com for more details!