Scientific and technological progress would not be possible without verifying theories, hypotheses, claims, and aspirations.
The Theranos blood testing scam case clearly shows that it is not enough to claim something works; you need to support it with hard facts and data.
When we do so, exciting positive results are important, but negative results are no less valuable: they prevent false premises from spreading and misleading, and they force us to explore other, better approaches that may lie in a completely different direction.
The aforementioned is a truism—except, it seems, it’s not in the field of data science and artificial intelligence (AI) related to translation!
In the field of medical AI research, an array of guardrails has been established to protect users from the implementation of under-verified AI models and systems; but in the field of translation this rigorous approach is absent, and in the field of AI for “just translation,” it is not uncommon to see claims supposedly proven on the basis of a narrow use case, limited data, unreliable conclusions, or extrapolations from totally unrelated situations. Often these claims are made without any data available for others to verify. Most often, the reason given for limiting public access to test data is “confidentiality,” which is hard to argue with.
Why does humanity carefully monitor medical AI, yet accept unverified claims about translation AI? Are we less concerned with what enters our minds than with what happens to our bodies during medical treatment?
Translation Quality Evaluation (TQE) is a fascinating area that lies at the crossroads of linguistics, metrology, data science, and other disciplines—it actually connects psycholinguistics, cognitive psychology, and neuroscience. Our brain is as complex and significant as our intestines, and we should show the same respect to linguists and translators as we do to medical professionals.
Collecting good data for TQE is challenging, particularly when it comes to gathering data from specific use cases where the data is processed, analyzed, and utilized in real-world production settings. Moreover, TQE outcomes vary based on the language pair, and the sheer number of language pairs adds another layer of complexity to the research.
Organizing human TQE takes time and requires communication among experts. However, large-scale production now demands translation at zero cost.
Automatic quality evaluation through “Translation Quality Prediction” using COMET seemed very promising in theory, but unfortunately, it shows little correlation between its claims and actual data.
This document provides a summary from one of the research labs focused on automatic quality prediction:
Beginning around 2020, each new reference-free quality estimation model that topped the WMT shared task was presented as having “solved” the problem. Industry interest rose accordingly. Yet, when those same models were evaluated on internal production data with proper statistical tests, the expected improvements failed to demonstrate strong statistical significance. In short, the level of community enthusiasm has grown faster than the empirical evidence.
Nevertheless, this same automatic quality prediction method is now being implemented in real-world production.
However, the hard truth is that enthusiasm and adoption by themselves do not guarantee that the method delivers as advertised.
Saying this is almost heresy at this stage of adoption, driven by unsubstantiated optimism, but the practical results from a real-world use case presented by Fred Bane this June provide a truly substantial counter-example to current claims.
To understand once and for all that sentence-level automatic prediction of translation quality cannot work, we need only to study the diagram in Figure 1 that visually represents real-world results. This is not just a chart; it is a picture of the total failure of the snake-oil solution called “automatic COMET-based sentence-level translation quality prediction.”
Here’s why.
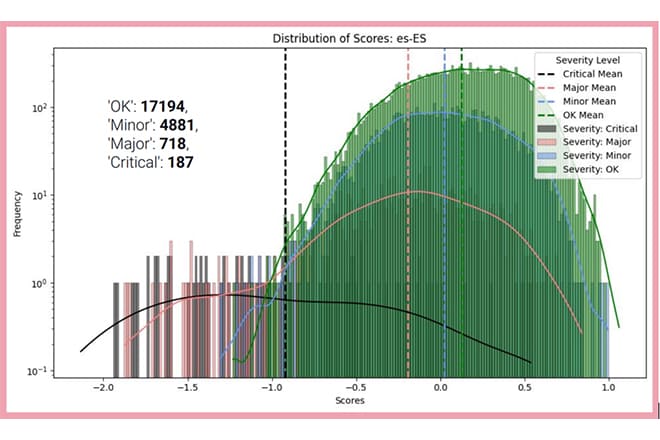
Fig. 1 Automatic translation quality prediction scores vs. actual error distributions. (COMET model wmt20-comet-qe-da). Note that Y-axis is in log scale.
At Logrus Global, my colleagues and I have conducted similar experiments and reached the same conclusions (contact rd@logrusglobal.com for details). So, I certainly commend Fred Bane for having the courage to challenge this unsubstantiated “automatic quality estimation” optimism and share the results of a process that I personally recognize as scientific:
“OK, let’s try the latest results. Let’s take our data, conduct a study, get human evaluators to annotate, and calculate the statistical significance of these results.”
This chart is based on an actual, unbiased experiment verifying these claims using real-world data.
“This plot comes from a client who translates technical documentation in enormous volumes. We’re talking about billions of words per year into 12 different languages, and the client truly cares about quality, conducting MQM-style reviews of much of their content. This means we have not only millions of sentences to work with per language, but also hundreds, thousands, or even tens of thousands of fully annotated sentences with quality evaluations and scores from expert linguists.”
In this chart, the sentences evaluated by linguists are grouped by their most severe error, and these groups are plotted together to see if it’s possible to separate the distributions. All critical errors are plotted together with major and minor errors, as well as sentences that are OK.
When these groups are plotted together, we observe that the system is kind of working, in the sense that the mean score of the sentences that required no edits whatsoever is higher than the mean score of the bucket containing sentences with minor errors. The mean for minor errors is higher than that for major errors, and the mean for major errors is much higher than that for critical errors—which is somewhat encouraging … However, there remains a significant “but.”
These distributions overlap almost completely.
There is no clear line (score) that can be drawn to separate all the critical errors from good sentences.
The horizontal axis in the plot uses a logarithmic scale to retain detail across a very large sample—about 20,000 segments in total, of which roughly 17,000 are error-free. Such a success rate is expected: the underlying MT engine has been extensively adapted to a single English-to-Spanish domain, one of the most favorable language pairs. Nevertheless, several hundred critical and major errors remain. When we look for a decision threshold that would reliably filter those serious errors out, none exists. Indeed, in some language pairs, the single highest-scoring segment according to COMET is a critical-error sentence. That reality makes a zero-post-editing workflow impossible if the goal is to guarantee that no critical errors receive a “Pass” rating.
A softer target is conceivable: one might settle for, say, 95% confidence that critical errors are caught. Given such a criterion, it becomes possible—depending on language and domain—to bypass post-editing for perhaps 20%–40% of the sentences. Yet even then, about 5% of critical errors would slip through, and many production environments judge that risk unacceptable.
Another huge challenge with using these quality estimation tools is that they are really unreliable at the segment level—precisely where they are touted to be useful in real translation workflows.
Sentence-level translation quality evaluation cannot be considered reliable due to the statistical nature of errors. This is clearly demonstrated in several papers, such as [1], [2].
Actual experiments involving large amounts of real data across various language pairs confirm that, at the level of an individual sentence (Translation Unit, TU), these scores are not reliable indicators for making decisions.
You cannot confidently say, “This translation scored X, which is above my threshold, so I’m going to approve it,” unless you are willing to accept the associated risk—such as the 5% chance of receiving a garbage translation instead of a correct one.
”We have no highly significant statistical correlation between quality estimation scores and any other metric we have—whether it be post-edit distance, the time the editor spent on the segment, the score the editor assigns, or anything else. We have never found a statistical correlation exceeding about 0.3 or 0.4 between a quality estimation score and any other measurable factor.”
Scores also vary across languages and content types.
Another frustrating issue is that these systems are completely unable to detect errors such as incorrect language or untranslated segments, which occur frequently. Untranslated sentences should receive a score of zero—or the worst possible score imaginable—but instead they consistently receive some of the highest scores. Why? Because an untranslated segment is identical to itself.
These significant challenges make it very difficult to derive substantial value from quality estimation in an industrial setting. As clients increasingly demand more automated work, they hope technology can bridge the gap and determine when human labor should be applied.
“Unfortunately, so far we have been unable to provide a reliable way to do so,” reflects the reality beneath the hype.
Still skeptical about how this real use case study can debunk claims that have been made so loudly?
Let’s dig a little deeper into the technical details of Unbabel models (you can skip this part if you are not technically inclined).
[start of technical part]
HuggingFace’s comment on https://huggingface.co/Unbabel/wmt20-comet-qe-da states: “Our model is intended to be used for reference-free MT evaluation. Given a source text and its translation, it outputs a single score that reflects the quality of the translation. The returned score is unbounded and noisy. It works well for ranking engines and translations over the same source but there is no clear interpretation of the resulting score.”
If the Kiwi model is so much better, why is this disclaimer omitted from the 2022 Kiwi model?
The “unbounded and noisy score / no clear interpretation” sentence disappeared from the COMET-Kiwi (2022) card because the model was changed, not because the warning stopped being relevant.
Kiwi’s authors:
1. Re-trained the model with additional objectives (word-level tags, critical-error detection, reference-based pre-training) that improved the correlation between a single sentence-level score and direct-assessment (DA) scores – see Rei et al., 2022 (and here we argue that DA is absolutely NOT a proper translation quality evaluation method to compare with);
2. Applied a calibration layer (a sigmoid function) to the raw regression output, so the final value is clipped to the range 0–1 and is monotonically related to DA (I actually informed Alon Lavie about this in 2020);
3. Reported that this bounded score is now “easier to read” and could be loosely interpreted as a quality probability. As a result, they rewrote the model card to state: “Outputs a single score between 0 and 1 where 1 represents a perfect translation.” (However, this is merely a description of sigmoid clipping to the [0, 1] interval, not a validation of the score’s reliability!)
BUT THE OLD CAVEATS STILL APPLY:
· Even with 0–1 scaling, Kiwi scores are relative: a score of 0.85 coming from “news → English” cannot be blindly compared with a 0.85 from “software UI → Japanese.”
· The number is not a guaranteed probability of correctness; it is still best used for ranking candidate translations produced for the same source.
· Kiwi’s authors caution that results “are unreliable” for language pairs outside InfoXLM’s pre-training set—another way of stating the same “no clear interpretation” limitation.
Correlation with human DA increased by several points over wmt20-comet-qe-da according to the WMT-22 shared-task leaderboard, but even 100% correlation with DA does NOT mean the score is reliable, since DA is an incorrect method for evaluating translation quality to begin with.
The bounded output makes it easier to define internal thresholds (e.g., > 0.75 = “high quality” in your pipeline), but normalizing to the [0, 1] interval is a trivial requirement, and this normalization alone does NOT mean that setting any threshold ensures that no critical errors are present in sentences with scores above the threshold, as this case study clearly demonstrates.
So, the absence of the exact disclaimer does not actually prove that the disclaimer is no longer valid. You should continue to treat Kiwi’s score as a heuristic, relative, and imprecise quality indicator—not an absolute certification of translation correctness.
AND, as this case study clearly shows, you cannot use such QE score to set up ANY quality threshold for individual sentence that ensures no critical errors are passing through or eliminates the need for 100% post-editing!
[end of the technical part]
Therefore, conclusions regarding “quality estimation” that are supported by SUBSTANTIAL real-world evidence are as follows:
Hard facts (along with my own conclusions—please form your own ones as well):
· Automatic sentence-level quality evaluation based on COMET-like QE does not function reliably enough to be adopted in an industrial setting.
· There is NO threshold that both ensures critical errors do not slip through and eliminates the need for 100% post-editing. THEREFORE:
· You must post-edit 100 % of the material if you cannot accept the risk of critical errors passing through.
· Sentence-level quality evaluation by QE (such as QPS) is ineffective for the purpose of reducing the post-editing workload in any CAT tool or system.
· The “success” of the WMT task does not translate to real-world data.
· COMET-like QE is only effective at the population level.
· If you rely solely on COMET-like QE as your decision-making criterion at sentence level, a significant level of risk is unavoidable. You must carefully consider content types, use cases, and other factors, especially where such risks—or any risks—are unacceptable.
For more information, please refer to Fred Bane’s presentation on the challenges of applying QE at scale, “QE and Risk Management,” at the ATA event “AI Safety in T&I” (https://www.atanet.org/event/ai-safety-in-translation-and-interpreting-standards-ethics-and-practical-implications/). You are also welcome to contact me directly for further explanations, clarifications, and references to the papers and studies supporting the points made above—for example, statistical evidence explaining why segment-level translation quality scores cannot work in principle and are inherently flawed, regardless of how they are constructed.
References:
[1] The Multi-Range Theory of Translation Quality Measurement: MQM scoring models and Statistical Quality Control, Gladkoff et.al.
https://arxiv.org/abs/2405.16969
[2] Measuring Uncertainty in Translation Quality Evaluation (TQE), Gladkoff et.al.
https://arxiv.org/abs/2111.07699