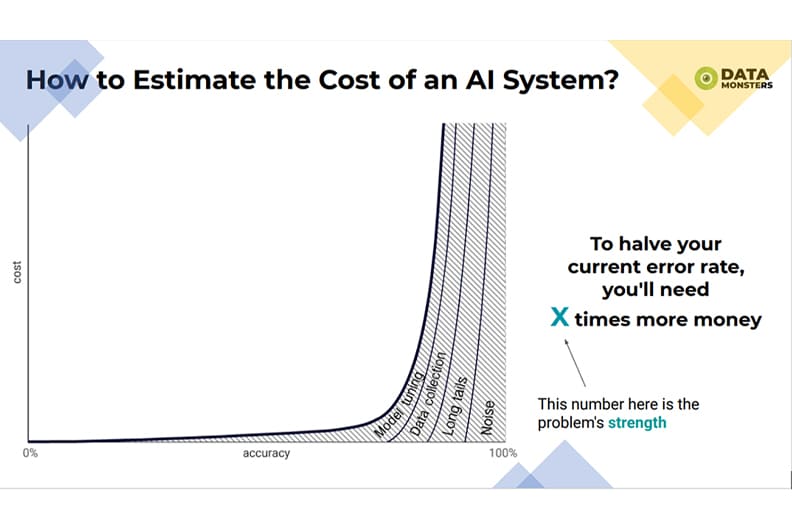
The inventor and visionary Ray Kurzweil, who coined the very term “singularity”, based his predictions on observation that today’s world is not linear.
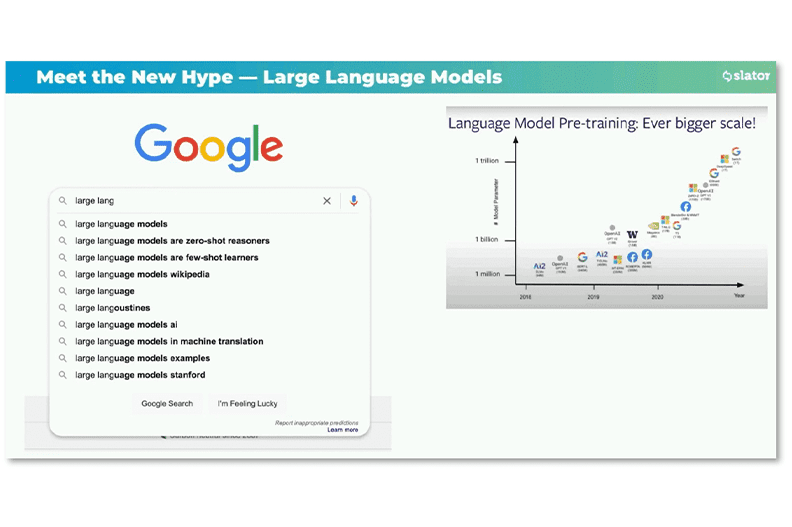
On November 10, 2021 Meta AI Research published article “The first-ever multilingual model to win WMT, beating out bilingual models”.

In recent public discourse, claims were made that the need no longer exists to measure translation quality.

Jost Zetzsche has featured Paralela aligner in recent issue of Toolbox Journal. The article reads:

Google Research in cooperation with MIT Media Lab published new research “Toward More Effective Human Evaluation for Machine Translation”
Sept 1, 2021 – In today’s data-driven world, high-quality bilingual data is a necessity for training better translation models as well as for capturing domain-specific knowledge
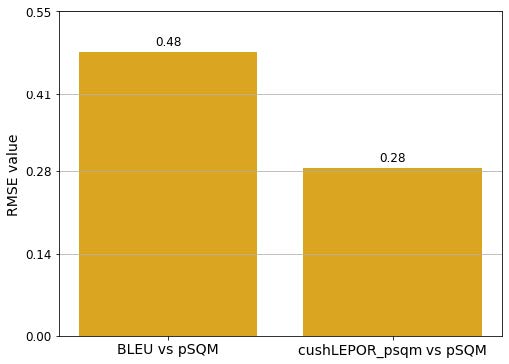
Automatic MT evaluation metrics are indispensable for MT research. Augmented metrics such as hLEPOR include broader evaluation factors (recall and position difference penalty)…

In the middle of the May holidays, on May 6, Slator, the industry’s largest news portal, published an overview post about a Google research team’s report, the significance of which the industry still needs to understand.