
The hype ignores AI hallucination, because the hype is caused by people hallucinating on AI.

“The unpredictable abilities emerging from large AI models: Large language models like ChatGPT are now big enough that they’ve started to display startling, unpredictable behaviors.”

We live in the world of hype. It is rarely completely harmless, but it is especially detrimental when it is accepted without scientific verification, and used as the basis for long-term growth plans.

A well-known philosopher and historian Yuval Noah Harai has penned a comment for The Economist, decrying the advent of AI as the end of human history.

For years, large clients have been attempting to stream content for translation.

The takeaway: Size is not the Answer Watch the video outlining the results of our participation in […]
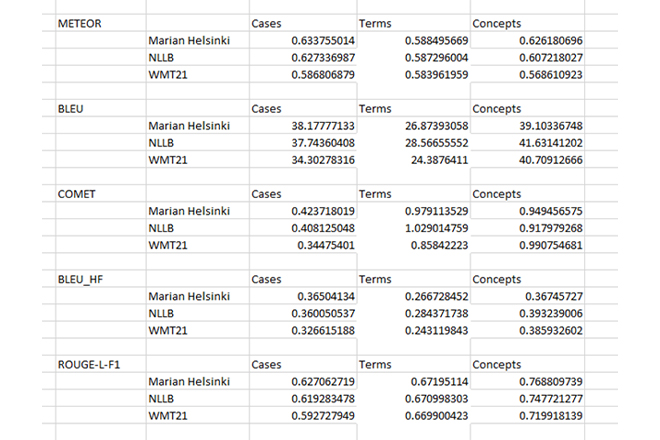
Last two weeks we participated in BiomedicalMT challenge for wmt22, and our MT model leads
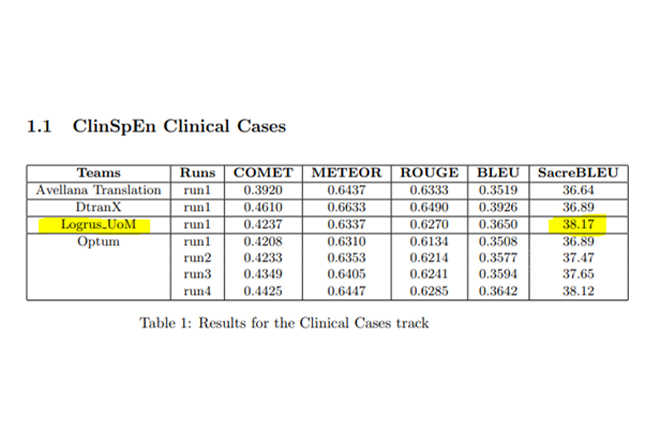
We participated in BiomedicalMT challenge for wmt22, and our MT model leads in Clinical Cases