Scientific and technological progress would not be possible without verifying theories, hypotheses, claims, and aspirations.

A week ago, on May 7, 2025, Y Combinator updated its Request for Startups (RFS), highlighting 14 strategic directions they consider especially promising.

This paper is actually only my notes of presentation “A Formal Perspective On Language Models”, given by Ryan Cotterell, assistant professor at ETH Zürich in the Department of Computer Science

Data scientists seem to believe that a magic Genie in the form of AI exists, and all you

As I watched the recent video presentation of the Quality Performance Score (QPS)

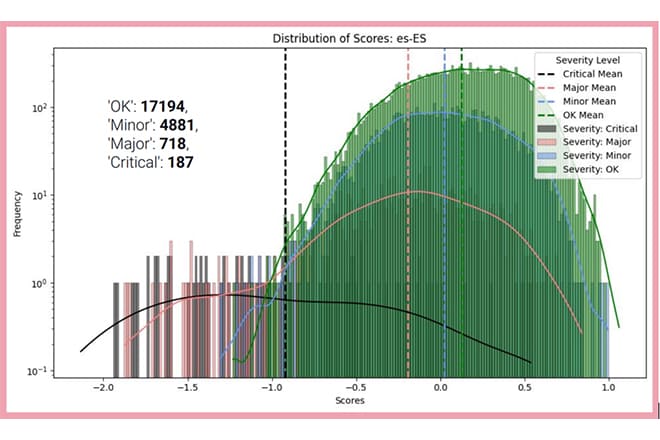
In our quest to provide the best services to our clients and utilize the abilities of machine translation to the utmost
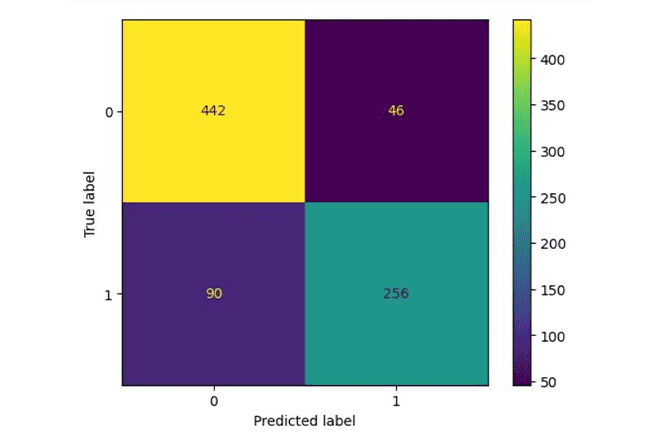
As 2023 draws to a close, it’s a perfect time to talk about year-end results – and we have something very special up our sleeve.
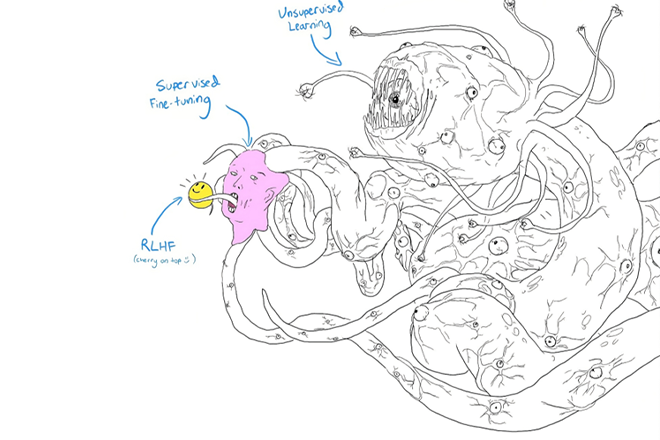
Generative LLMs, colloquially known as “AI”, have made great strides in the recent months – but that doesn’t mean that they became “intelligent” or that they stopped “hallucinating” and producing inaccurate answers or translations.